Die Varianz wird als Differenz berechnet. Berechnung der Gruppen-, Intergruppen- und Gesamtvarianz (nach der Regel der Addition von Varianzen)
Lösung.
Als Maß für die Streuung von Werten zufällige Variable gebraucht Streuung
Streuung (das Wort Streuung bedeutet „Streuung“) ist Maß für die Streuung zufälliger Variablenwerte relativ zu seiner mathematischen Erwartung. Dispersion ist der mathematische Erwartungswert der quadratischen Abweichung einer Zufallsvariablen von ihrem mathematischen Erwartungswert
Wenn die Zufallsvariable diskret ist und eine unendliche, aber abzählbare Menge von Werten hat, dann
wenn die Reihe auf der rechten Seite der Gleichheit konvergiert.
Eigenschaften der Dispersion.
- 1. Die Varianz eines konstanten Wertes ist Null
- 2. Die Varianz der Summe der Zufallsvariablen ist gleich der Summe der Varianzen
- 3. Der konstante Faktor kann aus dem Vorzeichen der quadrierten Streuung entnommen werden
Die Varianz der Differenz von Zufallsvariablen ist gleich der Summe der Varianzen
Diese Eigenschaft ist eine Folge der zweiten und dritten Eigenschaft. Abweichungen können sich nur summieren.
Es ist praktisch, die Dispersion mithilfe einer Formel zu berechnen, die sich leicht aus den Eigenschaften der Dispersion ermitteln lässt
Varianz ist immer positiv.
Die Varianz hat Abmessungen quadrierte Dimension der Zufallsvariablen selbst, was nicht immer praktisch ist. Daher die Menge
Standardabweichung(Standardabweichung oder Standard) einer Zufallsvariablen genannt wird arithmetischer Wert die Quadratwurzel seiner Varianz
Werfen Sie zwei Münzen im Wert von 2 und 5 Rubel. Wenn die Münze als Wappen landet, werden null Punkte vergeben, und wenn sie als Zahl landet, dann entspricht die Anzahl der Punkte dem Nennwert der Münze. Ermitteln Sie den mathematischen Erwartungswert und die Varianz der Punktzahl.
Lösung. Lassen Sie uns zunächst die Verteilung der Zufallsvariablen X ermitteln – die Anzahl der Punkte. Alle Kombinationen – (2;5),(2;0),(0;5),(0;0) – sind gleich wahrscheinlich und das Verteilungsgesetz lautet:

Wir ermitteln die Varianz mithilfe der Formel
warum rechnen wir
Beispiel 2.
Finden Sie eine unbekannte Wahrscheinlichkeit R, mathematischer Erwartungswert und Varianz einer diskreten Zufallsvariablen, die durch eine Wahrsangegeben wird
Wir finden den mathematischen Erwartungswert und die Varianz:
M(X) = 00,0081 + 10,0756 + 20,2646 + 3 0,4116 + +40,2401=2,8
Zur Berechnung der Streuung verwenden wir die Formel (19.4)
D(X) = 020 ,0081 + 120,0756 + 220,2646 + 320,4116 + 420,2401 - 2,82 = 8,68 -

Beispiel 3. Zwei gleichstarke Athleten veranstalten ein Turnier, das entweder bis zum ersten Sieg eines von ihnen dauert oder bis fünf Spiele gespielt wurden. Die Wahrscheinlichkeit, für jeden der Athleten ein Spiel zu gewinnen, beträgt 0,3 und die Wahrscheinlichkeit eines Unentschiedens beträgt 0,4. Finden Sie das Verteilungsgesetz, den mathematischen Erwartungswert und die Streuung der Anzahl der gespielten Spiele.
Lösung. Zufälliger Wert X- Die Anzahl der gespielten Spiele nimmt Werte von 1 bis 5 an, d. h.
Lassen Sie uns die Wahrscheinlichkeiten bestimmen, mit denen das Spiel beendet wird. Das Spiel endet mit dem ersten Satz, wenn einer ihrer Athleten gewinnt. Die Gewinnwahrscheinlichkeit beträgt
R(1) = 0,3+0,3 =0,6.
Gab es ein Unentschieden (die Wahrscheinlichkeit eines Unentschiedens beträgt 1 - 0,6 = 0,4), geht das Spiel weiter. Das Spiel endet im zweiten Spiel, wenn das erste unentschieden endete und jemand das zweite gewann. Wahrscheinlichkeit
R(2) = 0,4 0,6=0,24.
Ebenso endet das Spiel mit dem dritten Spiel, wenn es zwei Unentschieden in Folge gab und erneut jemand gewann
R(3) = 0,4 0,4 0,6 = 0,096. R(4)= 0,4 0,4 0,4 0,6=0,0384.
Das fünfte Spiel ist das letzte in jeder Version.
R(5)= 1 - (R(1)+R(2)+R(3)+R(4)) = 0,0256.
Lasst uns alles in eine Tabelle eintragen. Das Verteilungsgesetz der Zufallsvariablen „Anzahl der gewonnenen Spiele“ hat die Form
Erwarteter Wert
Wir berechnen die Varianz mit der Formel (19.4)
Diskrete Standardverteilungen.
Binomialverteilung. Lassen Sie Bernoullis experimentelles Schema umsetzen: N identische unabhängige Experimente, in denen jeweils das Ereignis A kann mit konstanter Wahrscheinlichkeit auftreten P und wird nicht mit Wahrscheinlichkeit erscheinen
(siehe Vorlesung 18).
Anzahl der Vorkommen des Ereignisses A in diesen N Experimente gibt es eine diskrete Zufallsvariable X, deren mögliche Werte sind:
0; 1; 2; ... ;M; ... ; N.
Wahrscheinlichkeit des Auftretens M Ereignisse A in einer bestimmten Reihe von N Experimente mit und das Verteilungsgesetz einer solchen Zufallsvariablen ist durch die Bernoulli-Formel gegeben (siehe Vorlesung 18)
 |



Numerische Eigenschaften einer Zufallsvariablen X nach dem Binomialgesetz verteilt:

Wenn N ist großartig (), dann geht die Formel (19.6) in die Formel ein
und die tabellarische Gaußsche Funktion (die Wertetabelle der Gaußschen Funktion finden Sie am Ende von Vorlesung 18).
In der Praxis kommt es oft nicht auf die Eintrittswahrscheinlichkeit an sich an. M Veranstaltungen A in einer bestimmten Serie von N Experimente und die Wahrscheinlichkeit, dass das Ereignis A es wird nicht weniger erscheinen
Zeiten und nicht mehr als Zeiten, also die Wahrscheinlichkeit, dass X die Werte annimmt
Dazu müssen wir die Wahrscheinlichkeiten zusammenfassen
Wenn N ist großartig (), wenn sich die Formel (19.9) in eine Näherungsformel verwandelt

tabellarische Funktion. Tabellen finden Sie am Ende der Vorlesung 18.
Bei der Verwendung von Tabellen ist dies zu berücksichtigen
Beispiel 1. Ein Auto, das sich einer Kreuzung nähert, kann mit gleicher Wahrscheinlichkeit auf einer der drei Straßen A, B oder C weiterfahren. Fünf Autos nähern sich der Kreuzung. Ermitteln Sie die durchschnittliche Anzahl der Autos, die auf Straße A fahren, und die Wahrscheinlichkeit, dass drei Autos auf Straße B fahren.
Lösung. Die Anzahl der auf jeder Straße vorbeifahrenden Autos ist eine Zufallsvariable. Geht man davon aus, dass alle Autos, die sich der Kreuzung nähern, unabhängig voneinander fahren, dann verteilt sich diese Zufallsvariable nach dem Binomialgesetz mit
N= 5 und P = .
Daher entspricht die durchschnittliche Anzahl der Autos, die der Straße A folgen, der Formel (19.7)
und die gewünschte Wahrscheinlichkeit bei
Beispiel 2. Die Wahrscheinlichkeit eines Geräteausfalls beträgt bei jedem Test 0,1. Es werden 60 Tests des Gerätes durchgeführt. Wie groß ist die Wahrscheinlichkeit, dass ein Geräteausfall auftritt: a) 15 Mal; b) nicht mehr als 15 Mal?
A. Da die Anzahl der Tests 60 beträgt, verwenden wir Formel (19.8)
Gemäß Tabelle 1 des Anhangs zu Vorlesung 18 finden wir
B. Wir verwenden Formel (19.10).
Gemäß Tabelle 2 des Anhangs zu Vorlesung 18
- - 0,495
- 0,49995
Poisson-Verteilung (Gesetz seltener Ereignisse). Wenn N groß und R little () und das Produkt usw behält einen konstanten Wert, den wir mit l bezeichnen,
dann wird Formel (19.6) zur Poisson-Formel

Das Poisson-Verteilungsgesetz hat die Form:

Offensichtlich ist die Definition des Poissonschen Gesetzes richtig, weil Haupteigenschaft einer Verteilerreihe
Fertig, weil Summe der Serien
Die Reihenentwicklung der Funktion at
Satz. Der mathematische Erwartungswert und die Varianz einer nach dem Poissonschen Gesetz verteilten Zufallsvariablen fallen zusammen und sind gleich dem Parameter dieses Gesetzes, d. h.
Nachweisen.
Beispiel. Um seine Produkte auf dem Markt zu bewerben, platziert das Unternehmen Flyer in Briefkästen. Die bisherigen Erfahrungen zeigen, dass in etwa einem von 2.000 Fällen eine Anordnung erfolgt. Ermitteln Sie die Wahrscheinlichkeit, dass bei der Platzierung von 10.000 Anzeigen mindestens eine Bestellung eintrifft, die durchschnittliche Anzahl der eingegangenen Bestellungen und die Varianz der Anzahl der eingegangenen Bestellungen.
Lösung. Hier
Die Wahrscheinlichkeit, dass mindestens eine Bestellung eintrifft, ermitteln wir durch die Wahrscheinlichkeit des gegenteiligen Ereignisses, d. h.
Zufälliger Ablauf von Ereignissen. Ein Ereignisstrom ist eine Abfolge von Ereignissen, die in auftreten zufällige Momente Zeit. Typische Beispiele für Ströme sind Ausfälle in Computernetzwerken, Anrufe bei Telefonzentralen, ein Fluss von Anfragen zur Gerätereparatur usw.
Fließen Ereignisse heißt stationär, wenn die Wahrscheinlichkeit, dass eine bestimmte Anzahl von Ereignissen in ein Zeitintervall der Länge fällt, nur von der Länge des Intervalls abhängt und nicht von der Position des Zeitintervalls auf der Zeitachse abhängt.
Die Stationaritätsbedingung wird durch den Anforderungsfluss erfüllt, dessen probabilistische Eigenschaften nicht von der Zeit abhängen. Ein stationärer Fluss zeichnet sich insbesondere durch eine konstante Dichte (die durchschnittliche Anzahl von Anfragen pro Zeiteinheit) aus. In der Praxis kommt es häufig zu Anfrageströmen, die (zumindest für einen begrenzten Zeitraum) als stationär betrachtet werden können. Beispielsweise kann der Anruffluss an einer städtischen Telefonzentrale im Zeitraum von 12 bis 13 Stunden als Festnetz betrachtet werden. Der gleiche Fluss über einen ganzen Tag hinweg kann nicht mehr als stationär angesehen werden (nachts ist die Anrufdichte deutlich geringer als tagsüber).
Fließen Ereignisse wird als Stream bezeichnet ohne Nachwirkung, wenn für alle nicht überlappenden Zeiträume die Anzahl der Ereignisse, die auf einen von ihnen fallen, nicht von der Anzahl der Ereignisse abhängt, die auf die anderen fallen.
Die Bedingung der Abwesenheit von Nachwirkungen – die wichtigste Voraussetzung für den einfachsten Ablauf – bedeutet, dass Anwendungen unabhängig voneinander in das System gelangen. Beispielsweise kann ein Passagierstrom, der eine U-Bahn-Station betritt, als ein Fluss ohne Nachwirkungen betrachtet werden, da die Gründe, die dazu führten, dass ein einzelner Passagier zu einem bestimmten Zeitpunkt und nicht zu einem anderen Zeitpunkt ankam, in der Regel nicht mit ähnlichen Gründen für andere Passagiere zusammenhängen . Allerdings kann die Bedingung der Nachwirkungslosigkeit aufgrund des Anscheins einer solchen Abhängigkeit leicht verletzt werden. Beispielsweise kann der Fluss der Passagiere, die eine U-Bahn-Station verlassen, nicht länger als Fluss ohne Nachwirkungen betrachtet werden, da die Ausstiegszeitpunkte der im selben Zug ankommenden Passagiere voneinander abhängig sind.
Fließen Ereignisse heißt normal, wenn die Wahrscheinlichkeit, dass zwei oder mehr Ereignisse innerhalb eines kurzen Zeitintervalls t auftreten, im Vergleich zur Wahrscheinlichkeit des Auftretens eines Ereignisses vernachlässigbar ist (in diesem Zusammenhang wird das Poissonsche Gesetz als Gesetz der seltenen Ereignisse bezeichnet).
Die Gewöhnlichkeitsbedingung bedeutet, dass Aufträge einzeln eintreffen und nicht in Paaren, Drillingen usw. Varianzabweichung Bernoulli-Verteilung
Beispielsweise kann der Kundenstrom, der einen Friseursalon betritt, als nahezu normal angesehen werden. Wenn in einem außergewöhnlichen Fluss Anwendungen nur paarweise, nur in Drillingen usw. eintreffen, kann der außerordentliche Fluss leicht auf einen gewöhnlichen reduziert werden; Dazu reicht es aus, einen Strom von Paaren, Drillingen usw. zu berücksichtigen, anstatt einen Strom von Einzelanfragen. Schwieriger wird es, wenn sich herausstellen kann, dass jede Anfrage zufällig doppelt, dreifach usw. ist. Dann müssen Sie sich mit einem Strom nicht homogener, sondern heterogener Ereignisse befassen.
Wenn ein Ereignisstrom alle drei Eigenschaften aufweist (d. h. stationär, gewöhnlich und ohne Nachwirkung), wird er als einfacher (oder stationärer Poisson-)Strom bezeichnet. Der Name „Poisson“ ist auf die Tatsache zurückzuführen, dass bei Erfüllung der aufgeführten Bedingungen die Anzahl der Ereignisse, die auf ein beliebiges festes Zeitintervall fallen, verteilt wird Poissons Gesetz
Hier ist die durchschnittliche Anzahl der Veranstaltungen A, erscheint pro Zeiteinheit.
Dieses Gesetz ist einparametrig, d.h. Um ihn einzustellen, müssen Sie nur einen Parameter kennen. Es kann gezeigt werden, dass Erwartungswert und Varianz im Poissonschen Gesetz numerisch gleich sind:
Beispiel. Nehmen wir an, mitten am Arbeitstag beträgt die durchschnittliche Anzahl der Anfragen 2 pro Sekunde. Wie groß ist die Wahrscheinlichkeit, dass 1) in einer Sekunde keine Bewerbungen eingehen, 2) in zwei Sekunden 10 Bewerbungen eintreffen?
Lösung. Da die Gültigkeit der Anwendung des Poissonschen Gesetzes außer Zweifel steht und sein Parameter gegeben ist (= 2), reduziert sich die Lösung des Problems auf die Anwendung der Poissonschen Formel (19.11).
1) T = 1, M = 0:
2) T = 2, M = 10:
Gesetz der großen Zahlen. Die mathematische Grundlage dafür, dass sich die Werte einer Zufallsvariablen um einige konstante Werte gruppieren, ist das Gesetz der großen Zahlen.
Historisch gesehen war die erste Formulierung des Gesetzes der großen Zahlen der Satz von Bernoulli:
„Mit einer unbegrenzten Zunahme der Anzahl identischer und unabhängiger Experimente n konvergiert die Häufigkeit des Auftretens von Ereignis A in der Wahrscheinlichkeit seiner Wahrscheinlichkeit“, d. h.
wo ist die Häufigkeit des Auftretens von Ereignis A in n Experimenten,
Im Wesentlichen bedeutet Ausdruck (19.10), dass wann große Zahl Experimentiert mit der Häufigkeit des Auftretens eines Ereignisses A kann die unbekannte Wahrscheinlichkeit dieses Ereignisses ersetzen, und je größer die Anzahl der durchgeführten Experimente ist, desto näher liegt p* an p. Interessant historische Tatsache. K. Pearson warf 12.000 Mal eine Münze und sein Wappen erschien 6.019 Mal (Häufigkeit 0,5016). Beim 24.000-maligen Werfen derselben Münze erhielt er 12.012 Wappen, d.h. Frequenz 0,5005.
Die wichtigste Form des Gesetzes der großen Zahlen ist der Satz von Tschebyschew: Bei einer unbegrenzten Zunahme der Anzahl unabhängiger Experimente mit endlicher Varianz, die unter identischen Bedingungen durchgeführt werden, konvergiert das arithmetische Mittel der beobachteten Werte der Zufallsvariablen in der Wahrscheinlichkeit seiner mathematischen Erwartung. In analytischer Form kann dieser Satz wie folgt geschrieben werden:
Neben seiner grundlegenden theoretischen Bedeutung hat der Satz von Tschebyschew auch wichtige praktische Anwendungen, beispielsweise in der Messtheorie. Nach n Messungen einer bestimmten Menge X, erhalten Sie verschiedene nicht übereinstimmende Werte X 1, X 2, ..., xn. Für den ungefähren Wert der gemessenen Größe X Bilden Sie das arithmetische Mittel der beobachteten Werte
Dabei, Je mehr Experimente durchgeführt werden, desto genauer wird das Ergebnis sein. Tatsache ist, dass die Streuung der Menge mit zunehmender Anzahl durchgeführter Experimente abnimmt, weil
D(X 1) = D(X 2)=…= D(xn) D(X) , Das
Die Beziehung (19.13) zeigt, dass es auch bei hoher Ungenauigkeit der Messgeräte (großer Wert) durch Erhöhung der Anzahl der Messungen möglich ist, ein Ergebnis mit beliebig hoher Genauigkeit zu erhalten.
Mithilfe der Formel (19.10) können Sie die Wahrscheinlichkeit ermitteln, dass die statistische Häufigkeit von der Wahrscheinlichkeit um nicht mehr als abweicht


Beispiel. Die Wahrscheinlichkeit eines Ereignisses in jedem Versuch beträgt 0,4. Wie viele Tests müssen Sie durchführen, um mit einer Wahrscheinlichkeit von nicht weniger als 0,8 zu erwarten, dass die relative Häufigkeit eines Ereignisses um weniger als 0,01 von der Wahrscheinlichkeit in absoluten Werten abweicht?
Lösung. Nach Formel (19.14)


daher gibt es laut Tabelle zwei Anwendungen
somit, N 3932.
Arten von Dispersionen:
Gesamtvarianz charakterisiert die Variation eines Merkmals der gesamten Bevölkerung unter dem Einfluss aller Faktoren, die diese Variation verursacht haben. Dieser Wert wird durch die Formel bestimmt
Wo ist das arithmetische Gesamtmittel der gesamten untersuchten Bevölkerung?
Durchschnittliche Varianz innerhalb der Gruppe bezeichnet eine zufällige Variation, die unter dem Einfluss nicht berücksichtigter Faktoren entstehen kann und die nicht von dem Faktorattribut abhängt, das die Grundlage der Gruppierung bildet. Diese Varianz wird wie folgt berechnet: Zuerst werden die Varianzen für einzelne Gruppen berechnet (), dann wird die durchschnittliche Varianz innerhalb der Gruppe berechnet:
 wobei n i die Anzahl der Einheiten in der Gruppe ist
wobei n i die Anzahl der Einheiten in der Gruppe ist
Intergruppenvarianz(Varianz der Gruppenmittelwerte) charakterisiert die systematische Variation, d.h. Unterschiede im Wert des untersuchten Merkmals, die unter dem Einfluss des Faktorzeichens entstehen, das der Gruppierung zugrunde liegt.

Wo ist der Durchschnittswert für eine separate Gruppe?
Alle drei Varianzarten hängen miteinander zusammen: Die Gesamtvarianz ist gleich der Summe der durchschnittlichen Varianz innerhalb der Gruppe und der Varianz zwischen den Gruppen:
![]()
Eigenschaften:
25 Relative Variationsmaße
|
Schwingungskoeffizient |
|
|
Relative lineare Abweichung |
|
|
Der Variationskoeffizient |
|
Coef. Osz. Ö spiegelt die relative Schwankung der Extremwerte eines Merkmals um den Durchschnitt wider. Rel. lin. aus. charakterisiert den Anteil des Mittelwerts am Vorzeichen der absoluten Abweichungen vom Durchschnittswert. Coef. Variation ist das am häufigsten verwendete Variabilitätsmaß zur Beurteilung der Typizität von Durchschnittswerten.
In der Statistik gelten Populationen mit einem Variationskoeffizienten von mehr als 30–35 % als heterogen.
Regelmäßigkeit der Verteilungsreihen. Momente der Verteilung. Indikatoren für die Verteilungsform
Bei Variationsreihen besteht ein Zusammenhang zwischen Häufigkeiten und Werten einer variierenden Charakteristik: Bei einer Zunahme der Charakteristik steigt der Häufigkeitswert zunächst bis zu einem bestimmten Grenzwert und nimmt dann ab. Solche Änderungen werden aufgerufen Verteilungsmuster.
Die Form der Verteilung wird anhand von Schiefe- und Kurtosis-Indikatoren untersucht. Bei der Berechnung dieser Indikatoren werden Verteilungsmomente verwendet.
Das Moment k-ter Ordnung ist der Durchschnitt der k-ten Abweichungsgrade der Variantenwerte eines Merkmals von einem konstanten Wert. Die Reihenfolge des Augenblicks wird durch den Wert von k bestimmt. Bei der Analyse von Variationsreihen beschränkt man sich auf die Berechnung der Momente der ersten vier Ordnungen. Bei der Berechnung von Momenten können Frequenzen oder Frequenzen als Gewichte verwendet werden. Abhängig von der Wahl des konstanten Wertes werden anfängliche, bedingte und zentrale Momente unterschieden.
Indikatoren für die Verteilungsform:
Asymmetrie(As) Indikator, der den Grad der Verteilungsasymmetrie charakterisiert .

Daher mit (linksseitiger) negativer Asymmetrie  . Mit (rechtsseitiger) positiver Asymmetrie
. Mit (rechtsseitiger) positiver Asymmetrie  .
.
Zentralmomente können zur Berechnung der Asymmetrie herangezogen werden. Dann:
 ,
,
wo μ 3 – zentraler Punkt dritte Ordnung.
- Kurtosis (E Zu ) charakterisiert die Steilheit des Funktionsgraphen im Vergleich zu Normalverteilung mit gleicher Variationsstärke:
 ,
,
wobei μ 4 das Zentralmoment 4. Ordnung ist.
Normalverteilungsgesetz
Für eine Normalverteilung (Gaußverteilung) hat die Verteilungsfunktion folgende Form:


Erwartung - Standardabweichung
Die Normalverteilung ist symmetrisch und wird durch die folgende Beziehung charakterisiert: Xav=Me=Mo
Die Kurtosis einer Normalverteilung beträgt 3 und der Schiefekoeffizient beträgt 0.
Die Normalverteilungskurve ist ein Polygon (symmetrische glockenförmige Gerade)
Arten von Dispersionen. Die Regel zum Addieren von Varianzen. Das Wesen des empirischen Bestimmtheitskoeffizienten.
Wenn die ursprüngliche Bevölkerung nach einem signifikanten Merkmal in Gruppen eingeteilt wird, dann berechnen Sie die folgenden Typen Dispersionen:
Gesamtvarianz der Originalpopulation:
wo ist total Durchschnittswert ursprüngliche Population; f – Häufigkeiten der ursprünglichen Population. Die Gesamtstreuung charakterisiert die Abweichung einzelner Werte eines Merkmals vom Gesamtdurchschnittswert der ursprünglichen Grundgesamtheit.
Varianzen innerhalb der Gruppe:
Dabei ist j die Nummer der Gruppe; der Durchschnittswert in jeder j-ten Gruppe; die Häufigkeit der j-ten Gruppe. Varianzen innerhalb der Gruppe charakterisieren die Abweichung des individuellen Werts eines Merkmals in jeder Gruppe vom Gruppendurchschnittswert. Aus allen Varianzen innerhalb der Gruppe wird der Durchschnitt mithilfe der Formel berechnet: wobei die Anzahl der Einheiten in jeder j-ten Gruppe ist.
Intergruppenvarianz:
Die Intergruppenstreuung charakterisiert die Abweichung der Gruppendurchschnitte vom Gesamtdurchschnitt der ursprünglichen Population.
Varianzadditionsregel ist, dass die Gesamtvarianz der ursprünglichen Grundgesamtheit gleich der Summe der Varianzen zwischen den Gruppen und dem Durchschnitt der Varianzen innerhalb der Gruppe sein sollte:
Empirisches Bestimmtheitsmaß zeigt den Anteil der Variation im untersuchten Merkmal aufgrund der Variation im Gruppierungsmerkmal und wird nach der Formel berechnet:
Methode des Zählens von einem bedingten Nullpunkt (Momentenmethode) zur Berechnung des Durchschnittswerts und der Varianz
Die Berechnung der Streuung nach der Momentenmethode basiert auf der Verwendung der Formel und den Eigenschaften 3 und 4 der Streuung.
(3. Wenn alle Werte des Attributs (Optionen) um eine konstante Zahl A erhöht (verringert) werden, ändert sich die Varianz der neuen Grundgesamtheit nicht.
4. Wenn alle Werte des Attributs (Optionen) um das K-fache erhöht (multipliziert) werden, wobei K eine konstante Zahl ist, dann erhöht (sinkt) die Varianz der neuen Grundgesamtheit um das K-fache.)
Wir erhalten eine Formel zur Berechnung der Streuung in Variationsreihen mit gleichen Intervallen nach der Momentenmethode:

A - bedingte Null, gleich der Option mit der maximalen Häufigkeit (die Mitte des Intervalls mit der maximalen Häufigkeit)
Auch die Berechnung des Durchschnittswertes nach der Momentenmethode basiert auf der Nutzung der Eigenschaften des Durchschnitts.
![]()
Das Konzept der selektiven Beobachtung. Phasen der Untersuchung wirtschaftlicher Phänomene mithilfe einer Stichprobenmethode
Eine Stichprobenbeobachtung ist eine Beobachtung, bei der nicht alle Einheiten der Grundgesamtheit, sondern nur ein Teil der Einheiten untersucht und untersucht werden und das Ergebnis der Untersuchung eines Teils der Grundgesamtheit für die gesamte Grundgesamtheit gilt. Die Grundgesamtheit, aus der Einheiten zur weiteren Untersuchung und Untersuchung ausgewählt werden, wird aufgerufen allgemein und alle Indikatoren, die diese Gesamtheit charakterisieren, werden aufgerufen allgemein.
Mögliche Grenzen der Abweichungen des Stichprobenmittelwerts vom allgemeinen Durchschnittswert werden genannt Stichprobenfehler.
Die Menge der ausgewählten Einheiten wird aufgerufen selektiv und alle Indikatoren, die diese Gesamtheit charakterisieren, werden aufgerufen selektiv.
Die Probenforschung umfasst die folgenden Phasen:
Merkmale des Untersuchungsgegenstandes (massenwirtschaftliche Phänomene). Wenn die Population klein ist, wird eine umfassende Untersuchung nicht empfohlen;
Berechnung der Stichprobengröße. Es ist wichtig, das optimale Volumen zu bestimmen, das es ermöglicht, dass der Probenahmefehler bei geringsten Kosten im akzeptablen Bereich liegt;
Auswahl der Beobachtungseinheiten unter Berücksichtigung der Anforderungen der Zufälligkeit und Verhältnismäßigkeit.
Nachweis der Repräsentativität basierend auf einer Schätzung des Stichprobenfehlers. Bei einer Zufallsstichprobe wird der Fehler anhand von Formeln berechnet. Für die Zielstichprobe wird die Repräsentativität anhand qualitativer Methoden (Vergleich, Experiment) beurteilt;
Analyse der Stichprobenpopulation. Erfüllt die generierte Stichprobe die Anforderungen an Repräsentativität, wird sie anhand analytischer Indikatoren (Durchschnitt, relativ usw.) analysiert.
Variationsbereich (oder Variationsbereich) - Dies ist die Differenz zwischen den Maximal- und Minimalwerten des Merkmals:
In unserem Beispiel beträgt die Schwankungsbreite der Schichtleistung der Arbeiter: in der ersten Brigade R = 105-95 = 10 Kinder, in der zweiten Brigade R = 125-75 = 50 Kinder. (5 mal mehr). Dies deutet darauf hin, dass die Leistung der 1. Brigade „stabiler“ ist, die zweite Brigade jedoch über mehr Reserven zur Leistungssteigerung verfügt, weil Wenn alle Arbeiter die maximale Leistung dieser Brigade erreichen, kann sie 3 * 125 = 375 Teile produzieren, in der 1. Brigade nur 105 * 3 = 315 Teile.
Wenn die Extremwerte eines Merkmals nicht typisch für die Grundgesamtheit sind, werden Quartil- oder Dezilbereiche verwendet. Der Quartilbereich RQ= Q3-Q1 deckt 50 % des Bevölkerungsvolumens ab, der erste Dezilbereich RD1 = D9-D1 deckt 80 % der Daten ab, der zweite Dezilbereich RD2= D8-D2 – 60 %.
Der Nachteil des Variationsbereichsindikators besteht darin, dass sein Wert nicht alle Schwankungen des Merkmals widerspiegelt.
Der einfachste allgemeine Indikator, der alle Schwankungen eines Merkmals widerspiegelt, ist durchschnittliche lineare Abweichung, das ist das arithmetische Mittel der absoluten Abweichungen einzelner Optionen von ihrem Durchschnittswert:
,
für gruppierte Daten ![]() ,
,
Dabei ist xi der Wert des Attributs in einer diskreten Reihe oder die Mitte des Intervalls in der Intervallverteilung.
In den obigen Formeln werden die Differenzen im Zähler modulo gebildet, andernfalls bleibt der Zähler entsprechend der Eigenschaft des arithmetischen Mittels immer gleich gleich Null. Daher wird die durchschnittliche lineare Abweichung in der statistischen Praxis selten verwendet, sondern nur dann, wenn die Summierung von Indikatoren ohne Berücksichtigung des Vorzeichens wirtschaftlich sinnvoll ist. Mit seiner Hilfe werden beispielsweise die Zusammensetzung der Belegschaft, die Rentabilität der Produktion und Außenhandelsumsätze analysiert.
Varianz eines Merkmals ist das durchschnittliche Quadrat der Abweichungen von ihrem Durchschnittswert:
einfache Varianz ![]() ,
,
Varianzgewichtet  .
.
Die Formel zur Berechnung der Varianz kann vereinfacht werden:
Somit ist die Varianz gleich der Differenz zwischen dem Mittelwert der Quadrate der Option und dem Quadrat des Mittelwerts der Populationsoption:  .
.
Aufgrund der Summation der quadrierten Abweichungen ergibt die Varianz jedoch ein verzerrtes Bild der Abweichungen, sodass der Durchschnitt auf dieser Grundlage berechnet wird Standardabweichung, die zeigt, wie stark bestimmte Varianten eines Merkmals im Durchschnitt von ihrem Durchschnittswert abweichen. Berechnet durch Ziehen der Quadratwurzel der Varianz:
für nicht gruppierte Daten 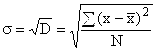 ,
,
für Variationsreihen 
Je kleiner der Wert der Varianz und der Standardabweichung ist, je homogener die Grundgesamtheit ist, desto zuverlässiger (typischer) ist der Durchschnittswert.
Durchschnittliche lineare und Standardabweichung sind benannte Zahlen, d. h. sie werden in Maßeinheiten eines Merkmals ausgedrückt, sind inhaltlich identisch und haben eine ähnliche Bedeutung.
Berechnung absolute Indikatoren Variationen werden anhand von Tabellen empfohlen.
Tabelle 3 – Berechnung der Variationsmerkmale (am Beispiel des Zeitraums der Daten zur Schichtleistung von Mannschaftsarbeitern)
Anzahl der Arbeiter |
Die Mitte des Intervalls |
Berechnete Werte |
|||||
Gesamt: |
|||||||
Durchschnittliche Schichtleistung der Arbeiter: ![]()
Durchschnittliche lineare Abweichung: ![]()
Produktionsabweichung: 
Die Standardabweichung der Leistung einzelner Arbeitnehmer von der durchschnittlichen Leistung:
.
1 Berechnung der Streuung nach der Momentenmethode
Die Berechnung von Varianzen erfordert umständliche Berechnungen (insbesondere, wenn der Durchschnittswert ausgedrückt wird). eine große Anzahl mit mehreren Nachkommastellen). Berechnungen können durch die Verwendung einer vereinfachten Formel und Dispersionseigenschaften vereinfacht werden.
Die Dispersion hat folgende Eigenschaften:
- Wenn alle Werte eines Merkmals um denselben Wert A verringert oder erhöht werden, verringert sich die Streuung nicht:
 ,
,
 , dann oder
, dann oder 
Indem wir die Eigenschaften der Streuung nutzen und zunächst alle Varianten der Grundgesamtheit um den Wert A reduzieren und dann durch den Wert des Intervalls h dividieren, erhalten wir eine Formel zur Berechnung der Streuung in Variationsreihen mit gleichen Intervallen Art und Weise der Momente: ,
,
wo wird die Streuung nach der Momentenmethode berechnet?
h – Wert des Intervalls der Variationsreihe;
– Option für neue (transformierte) Werte;
A ist ein konstanter Wert, der als Mitte des Intervalls mit der höchsten Häufigkeit verwendet wird; oder die Option mit der höchsten Häufigkeit; 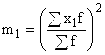 – Quadrat des Moments erster Ordnung;
– Quadrat des Moments erster Ordnung;
– Moment zweiter Ordnung.
Berechnen wir die Streuung mithilfe der Momentenmethode basierend auf Daten über die Schichtleistung der Mitarbeiter des Teams.
Tabelle 4 – Berechnung der Varianz mit der Momentenmethode
Gruppen von Produktionsarbeitern, Stk. |
Anzahl der Arbeiter |
Die Mitte des Intervalls |
Berechnete Werte |
||
Berechnungsverfahren:


- Wir berechnen die Varianz:
2 Berechnung der Varianz eines alternativen Merkmals
Unter den von der Statistik untersuchten Merkmalen gibt es solche, die nur zwei sich gegenseitig ausschließende Bedeutungen haben. Dies sind alternative Zeichen. Sie erhalten jeweils zwei quantitative Werte: Option 1 und 0. Die Häufigkeit von Option 1, die mit p bezeichnet wird, ist der Anteil der Einheiten, die dieses Merkmal besitzen. Die Differenz 1-ð=q ist die Häufigkeit der Optionen 0. Somit ist
xi |
|
Arithmetisches Mittel des Alternativzeichens ![]() , weil p+q=1.
, weil p+q=1.
Alternative Merkmalsvarianz
, Weil 1-ð=q
Somit ist die Varianz eines alternativen Merkmals gleich dem Produkt aus dem Anteil der Einheiten, die dieses Merkmal besitzen, und dem Anteil der Einheiten, die dieses Merkmal nicht besitzen.
Treten die Werte 1 und 0 gleich häufig auf, also p=q, erreicht die Varianz ihr Maximum pq=0,25.
Die Varianz eines Alternativmerkmals wird in Stichprobenerhebungen beispielsweise zur Produktqualität verwendet.
3 Varianz zwischen Gruppen. Varianzadditionsregel
Im Gegensatz zu anderen Variationsmerkmalen handelt es sich bei der Dispersion um eine additive Größe. Das heißt, im Aggregat, das nach Faktormerkmalen in Gruppen eingeteilt wird X , Varianz des resultierenden Merkmals j kann in die Varianz innerhalb jeder Gruppe (innerhalb von Gruppen) und die Varianz zwischen Gruppen (zwischen Gruppen) zerlegt werden. Dann wird es neben der Untersuchung der Variation eines Merkmals in der gesamten Population auch möglich, die Variation in jeder Gruppe sowie zwischen diesen Gruppen zu untersuchen.
Gesamtvarianz misst die Variation eines Merkmals bei in seiner Gesamtheit unter dem Einfluss aller Faktoren, die diese Variation (Abweichungen) verursacht haben. Sie entspricht der mittleren quadratischen Abweichung einzelner Werte des Attributs bei aus dem Gesamtdurchschnitt und kann als einfache oder gewichtete Varianz berechnet werden.
Intergruppenvarianz charakterisiert die Variation des resultierenden Merkmals bei verursacht durch den Einfluss des Faktorzeichens X, die die Grundlage der Gruppierung bildete. Es charakterisiert die Variation der Gruppendurchschnitte und entspricht dem mittleren Quadrat der Abweichungen der Gruppendurchschnitte vom Gesamtdurchschnitt:  ,
,
wo ist das arithmetische Mittel der i-ten Gruppe;
– Anzahl der Einheiten in der i-ten Gruppe (Häufigkeit der i-ten Gruppe);
– der Gesamtdurchschnitt der Bevölkerung.
Varianz innerhalb der Gruppe spiegelt die zufällige Variation wider, d. h. den Teil der Variation, der durch den Einfluss nicht berücksichtigter Faktoren verursacht wird und nicht von dem Faktorattribut abhängt, das die Grundlage der Gruppierung bildet. Es charakterisiert die Variation einzelner Werte relativ zu Gruppendurchschnitten und ist gleich der mittleren quadratischen Abweichung einzelner Werte des Attributs bei innerhalb einer Gruppe aus dem arithmetischen Mittel dieser Gruppe (Gruppenmittel) und wird als einfache oder gewichtete Varianz für jede Gruppe berechnet: ![]() oder
oder ![]() ,
,
Wo ist die Anzahl der Einheiten in der Gruppe?
Basierend auf den gruppeninternen Varianzen für jede Gruppe kann man bestimmen Gesamtmittelwert der gruppeninternen Varianzen:
.
Den Zusammenhang zwischen den drei Streuungen nennt man Regeln zum Addieren von Varianzen, wonach die Gesamtvarianz gleich der Summe der Varianz zwischen den Gruppen und dem Durchschnitt der Varianzen innerhalb der Gruppe ist:
Beispiel. Beim Studium des Einflusses Tarifkategorie(Qualifikationen) der Arbeitnehmer auf dem Niveau der Produktivität ihrer Arbeit wurden die folgenden Daten erhalten.
Tabelle 5 – Verteilung der Arbeitnehmer nach durchschnittlicher Stundenleistung.
№ p/p |
Arbeiter der 4. Kategorie |
Arbeiter der 5. Kategorie |
|||||
Ausgabe |
Ausgabe |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
IN in diesem Beispiel Arbeitnehmer werden nach Faktormerkmalen in zwei Gruppen eingeteilt X– Qualifikationen, die durch ihren Rang gekennzeichnet sind. Das resultierende Merkmal – die Produktion – variiert sowohl unter seinem Einfluss (Intergruppenvariation) als auch aufgrund anderer Zufallsfaktoren (Intragruppenvariation). Das Ziel besteht darin, diese Variationen anhand von drei Varianzen zu messen: insgesamt, zwischen Gruppen und innerhalb von Gruppen. Das empirische Bestimmtheitsmaß gibt den Variationsanteil des resultierenden Merkmals an bei unter dem Einfluss eines Faktorzeichens X. Rest der Gesamtvariante bei verursacht durch Veränderungen anderer Faktoren.
Im Beispiel beträgt das empirische Bestimmtheitsmaß: ![]() oder 66,7 %,
oder 66,7 %,
Dies bedeutet, dass 66,7 % der Unterschiede in der Arbeitsproduktivität auf Qualifikationsunterschiede zurückzuführen sind und 33,3 % auf den Einfluss anderer Faktoren zurückzuführen sind.
Empirische Korrelationsbeziehung zeigt den engen Zusammenhang zwischen Gruppierung und Leistungsmerkmalen. Berechnet als Quadratwurzel des empirischen Bestimmtheitsmaßes:
Das empirische Korrelationsverhältnis kann Werte von 0 bis 1 annehmen.
Wenn keine Verbindung besteht, dann =0. In diesem Fall =0, d. h. die Gruppenmittelwerte sind einander gleich und es gibt keine Variation zwischen den Gruppen. Dies bedeutet, dass das Gruppierungsmerkmal - Faktor keinen Einfluss auf die Bildung allgemeiner Variation hat.
Wenn die Verbindung funktionsfähig ist, dann =1. In diesem Fall ist die Varianz der Gruppenmittelwerte gleich der Gesamtvarianz (), d. h. es gibt keine Variation innerhalb der Gruppe. Dies bedeutet, dass das Gruppierungsmerkmal vollständig die Variation des untersuchten resultierenden Merkmals bestimmt.
Je näher der Wert des Korrelationsverhältnisses an Eins liegt, desto näher, näher an der funktionalen Abhängigkeit, ist der Zusammenhang zwischen den Merkmalen.
Um die Nähe des Zusammenhangs zwischen Merkmalen qualitativ zu beurteilen, werden Chaddock-Relationen verwendet.
Im Beispiel ![]() , was auf einen engen Zusammenhang zwischen der Produktivität der Arbeitnehmer und ihren Qualifikationen hinweist.
, was auf einen engen Zusammenhang zwischen der Produktivität der Arbeitnehmer und ihren Qualifikationen hinweist.
Wird die Grundgesamtheit entsprechend dem untersuchten Merkmal in Gruppen eingeteilt, so können für diese Grundgesamtheit folgende Varianzarten berechnet werden: Gesamt, Gruppe (innerhalb der Gruppe), Durchschnitt der Gruppe (Durchschnitt der innerhalb der Gruppe), Intergruppe.
Zunächst wird der Bestimmtheitskoeffizient berechnet, der zeigt, welcher Teil der Gesamtvariation des untersuchten Merkmals eine Intergruppenvariation ist, d. h. aufgrund des Gruppierungsmerkmals:
Die empirische Korrelationsbeziehung charakterisiert die Nähe des Zusammenhangs zwischen Gruppierung (Fakultät) und Leistungsmerkmalen.
Das empirische Korrelationsverhältnis kann Werte von 0 bis 1 annehmen.
Um die Nähe des Zusammenhangs anhand des empirischen Korrelationsverhältnisses zu beurteilen, können Sie die Chaddock-Relationen verwenden:
Beispiel 4.Über die Arbeitsleistung der Planungs- und Vermessungsorganisationen liegen folgende Daten vor verschiedene Formen Eigentum:
Definieren:
1) Gesamtvarianz;
2) Gruppenvarianzen;
3) der Durchschnitt der Gruppenvarianzen;
4) Intergruppenvarianz;
5) Gesamtvarianz basierend auf der Regel zum Addieren von Varianzen;
6) Bestimmtheitsmaß und empirisches Korrelationsverhältnis.
Schlussfolgerungen.
Lösung:
1. Bestimmen wir das durchschnittliche Arbeitsvolumen von Unternehmen mit zwei Eigentumsformen:
Berechnen wir die Gesamtvarianz:
![]()
2. Gruppendurchschnitte ermitteln:
![]() Millionen Rubel;
Millionen Rubel;
![]() Millionen Rubel
Millionen Rubel
Gruppenabweichungen:
![]() ;
;
3. Berechnen Sie den Durchschnitt der Gruppenvarianzen:
4. Bestimmen wir die Intergruppenvarianz:
5. Berechnen Sie die Gesamtvarianz basierend auf der Regel zum Addieren von Varianzen:
6. Bestimmen wir das Bestimmtheitsmaß:
![]() .
.
So hängt der Umfang der von Planungs- und Vermessungsorganisationen geleisteten Arbeit zu 22 % von der Eigentumsform der Unternehmen ab.
Das empirische Korrelationsverhältnis wird anhand der Formel berechnet
![]() .
.
Der Wert des berechneten Indikators zeigt, dass die Abhängigkeit des Arbeitsvolumens von der Eigentumsform des Unternehmens gering ist.
Beispiel 5. Als Ergebnis einer Erhebung zur technologischen Disziplin der Produktionsbereiche wurden folgende Daten gewonnen:
Bestimmen Sie das Bestimmtheitsmaß
Dieses Merkmal allein reicht jedoch nicht aus, um eine Zufallsvariable zu untersuchen. Stellen wir uns zwei Schützen vor, die auf eine Zielscheibe schießen. Der eine schießt genau und trifft nah an der Mitte, während der andere... einfach nur Spaß hat und nicht einmal zielt. Aber das Lustige ist, dass er Durchschnitt Das Ergebnis wird genau das gleiche sein wie beim ersten Shooter! Diese Situation wird herkömmlicherweise durch die folgenden Zufallsvariablen veranschaulicht:
Die mathematische Erwartung des „Scharfschützen“ ist gleich, für die „interessante Person“ jedoch: - sie ist auch Null!
Daher muss quantifiziert werden, wie weit verstreut Aufzählungszeichen (zufällige Variablenwerte) relativ zur Mitte des Ziels (mathematische Erwartung). gut und Streuung aus dem Lateinischen übersetzt ist kein anderer Weg als Streuung .
Sehen wir uns anhand eines der Beispiele aus dem 1. Teil der Lektion an, wie dieses numerische Merkmal ermittelt wird: 
Dort haben wir eine enttäuschende mathematische Erwartung dieses Spiels gefunden, und jetzt müssen wir seine Varianz berechnen, die bezeichnet durch durch .
Lassen Sie uns herausfinden, wie weit die Gewinne/Verluste relativ zum Durchschnittswert „verstreut“ sind. Dafür müssen wir natürlich rechnen Unterschiede zwischen Zufallsvariablenwerte und sie mathematische Erwartung:
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
Nun scheint es notwendig zu sein, die Ergebnisse zusammenzufassen, aber diese Methode ist nicht geeignet, da sich Schwankungen nach links mit Schwankungen nach rechts gegenseitig aufheben. Also zum Beispiel ein „Amateur“-Schütze (Beispiel oben) Die Unterschiede werden sein ![]() , und wenn sie addiert werden, ergeben sie Null, sodass wir keine Schätzung der Streuung seiner Schüsse erhalten.
, und wenn sie addiert werden, ergeben sie Null, sodass wir keine Schätzung der Streuung seiner Schüsse erhalten.
Um dieses Problem zu umgehen, können Sie Folgendes in Betracht ziehen Module Unterschiede, aber aus technischen Gründen hat sich der Ansatz durchgesetzt, wenn man sie ins Gleichgewicht bringt. Bequemer ist es, die Lösung in einer Tabelle zu formulieren: 
Und hier heißt es rechnen gewichteter Durchschnitt der Wert der quadrierten Abweichungen. Was ist es? Es gehört ihnen erwarteter Wert, was ein Maß für die Streuung ist:
![]() – Definition Abweichungen. Aus der Definition geht das sofort hervor Die Varianz kann nicht negativ sein– zum Üben beachten!
– Definition Abweichungen. Aus der Definition geht das sofort hervor Die Varianz kann nicht negativ sein– zum Üben beachten!
Erinnern wir uns daran, wie man den erwarteten Wert findet. Multiplizieren Sie die quadrierten Differenzen mit den entsprechenden Wahrscheinlichkeiten (Tabellenfortsetzung):
– im übertragenen Sinne handelt es sich um „Zugkraft“,
und fassen Sie die Ergebnisse zusammen:
Finden Sie nicht, dass das Ergebnis im Vergleich zum Gewinn zu hoch ausgefallen ist? Das ist richtig – wir haben es geschafft, und um zur Dimension unseres Spiels zurückzukehren, müssen wir extrahieren Quadratwurzel. Diese Menge heißt Standardabweichung
und wird mit dem griechischen Buchstaben „Sigma“ bezeichnet:
Dieser Wert wird manchmal aufgerufen Standardabweichung .
Was ist seine Bedeutung? Wenn wir von der mathematischen Erwartung nach links und rechts um die Standardabweichung abweichen: ![]()
– dann werden die wahrscheinlichsten Werte der Zufallsvariablen auf dieses Intervall „konzentriert“. Was wir tatsächlich beobachten:
Es kommt jedoch vor, dass man bei der Analyse der Streuung fast immer mit dem Begriff der Streuung arbeitet. Lassen Sie uns herausfinden, was es in Bezug auf Spiele bedeutet. Wenn es bei Pfeilen um die „Genauigkeit“ von Treffern relativ zur Zielmitte geht, dann charakterisiert die Streuung hier zwei Dinge:
Erstens ist es offensichtlich, dass mit steigenden Einsätzen auch die Streuung zunimmt. Wenn wir also beispielsweise um das Zehnfache erhöhen, erhöht sich die mathematische Erwartung um das Zehnfache und die Varianz erhöht sich um das Hundertfache (da es sich um eine quadratische Größe handelt). Beachten Sie jedoch, dass sich die Spielregeln selbst nicht geändert haben! Nur die Kurse haben sich grob gesagt geändert, bevor wir 10 Rubel gesetzt haben, jetzt 100.
Der zweite, interessantere Punkt ist, dass Varianz den Spielstil charakterisiert. Legen Sie die Spielwetten im Geiste fest auf einem bestimmten Niveau, und mal sehen, was was ist:
Ein Spiel mit geringer Varianz ist ein vorsichtiges Spiel. Der Spieler tendiert dazu, die zuverlässigsten Schemata zu wählen, bei denen er nicht zu viel auf einmal verliert/gewinnt. Zum Beispiel das Rot/Schwarz-System beim Roulette (siehe Beispiel 4 des Artikels Zufällige Variablen) .
Spiel mit hoher Varianz. Sie wird oft angerufen dispersiv Spiel. Dies ist ein abenteuerlicher oder aggressiver Spielstil, bei dem der Spieler „Adrenalin“-Schemata wählt. Erinnern wir uns wenigstens daran „Martingal“, bei dem die auf dem Spiel stehenden Beträge um Größenordnungen größer sind als beim „ruhigen“ Spiel des vorherigen Punktes.
Die Situation beim Poker ist bezeichnend: Es gibt sogenannte eng Spieler, die dazu neigen, vorsichtig und „unsicher“ mit ihren Spielgeldern umzugehen (Bankroll). Es überrascht nicht, dass ihr Guthaben nicht wesentlich schwankt (geringe Varianz). Im Gegenteil: Wenn ein Spieler eine hohe Varianz aufweist, ist er ein Aggressor. Er geht oft Risiken ein, macht große Einsätze und kann entweder eine riesige Bank sprengen oder sich selbst in Stücke reißen.
Das Gleiche passiert im Devisenhandel und so weiter – es gibt viele Beispiele.
Darüber hinaus spielt es in allen Fällen keine Rolle, ob das Spiel um ein paar Cent oder Tausende von Dollar gespielt wird. Jedes Level hat seine Spieler mit niedriger und hoher Streuung. Nun, wie wir uns erinnern, ist der durchschnittliche Gewinn „verantwortungsvoll“. erwarteter Wert.
Sie haben wahrscheinlich bemerkt, dass die Ermittlung der Varianz ein langer und mühsamer Prozess ist. Aber die Mathematik ist großzügig:
Formel zum Ermitteln der Varianz
Diese Formel leitet sich direkt aus der Varianzdefinition ab und wir haben sie sofort angewendet. Ich kopiere das Schild mit unserem Spiel oben: 
und die gefundene mathematische Erwartung.
Berechnen wir die Varianz auf die zweite Art. Lassen Sie uns zunächst den mathematischen Erwartungswert ermitteln – das Quadrat der Zufallsvariablen. Von Bestimmung der mathematischen Erwartung:
IN in diesem Fall:
Also nach der Formel:
Wie sie sagen: Spüren Sie den Unterschied. Und in der Praxis ist es natürlich besser, die Formel zu verwenden (sofern die Bedingung nichts anderes erfordert).
Wir beherrschen die Technik des Lösens und Entwerfens:
Beispiel 6

Finden Sie den mathematischen Erwartungswert, die Varianz und die Standardabweichung.
Diese Aufgabe findet sich überall und ist in der Regel ohne sinnvolle Bedeutung.
Man kann sich mehrere Glühbirnen mit Zahlen vorstellen, die mit bestimmten Wahrscheinlichkeiten in einem Irrenhaus aufleuchten :)
Lösung: Es ist praktisch, die grundlegenden Berechnungen in einer Tabelle zusammenzufassen. Zuerst schreiben wir die Anfangsdaten in die oberen beiden Zeilen. Dann berechnen wir die Produkte, dann und zum Schluss die Summen in der rechten Spalte: 
Eigentlich ist fast alles fertig. Die dritte Zeile zeigt eine vorgefertigte mathematische Erwartung: ![]() .
.
Wir berechnen die Varianz nach der Formel:
Und schließlich die Standardabweichung:
– Ich persönlich runde normalerweise auf zwei Dezimalstellen.
Alle Berechnungen können auf einem Taschenrechner oder noch besser – in Excel durchgeführt werden:
Hier kann man kaum etwas falsch machen :)
Antwort:
Wer möchte, kann sein Leben noch weiter vereinfachen und von mir profitieren Taschenrechner (Demo), was dieses Problem nicht nur sofort löst, sondern auch baut thematische Grafiken (wir werden bald dort sein). Das Programm kann sein aus der Bibliothek herunterladen– wenn Sie mindestens ein Lehrmaterial heruntergeladen haben oder erhalten ein anderer Weg. Vielen Dank für die Unterstützung des Projekts!
Ein paar Aufgaben, die Sie selbst lösen können:
Beispiel 7
Berechnen Sie per Definition die Varianz der Zufallsvariablen im vorherigen Beispiel.
Und ein ähnliches Beispiel:
Beispiel 8
Eine diskrete Zufallsvariable wird durch ihr Verteilungsgesetz spezifiziert:

Ja, Zufallsvariablenwerte können ziemlich groß sein (Beispiel aus realer Arbeit), und hier, wenn möglich, Excel verwenden. Wie übrigens auch in Beispiel 7 – es ist schneller, zuverlässiger und angenehmer.
Lösungen und Antworten unten auf der Seite.
Zum Abschluss des 2. Teils der Lektion betrachten wir ein weiteres typisches Problem, man könnte sogar sagen ein kleines Rätsel:
Beispiel 9
Eine diskrete Zufallsvariable kann nur zwei Werte annehmen: und , und . Die Wahrscheinlichkeit, der mathematische Erwartungswert und die Varianz sind bekannt.
Lösung: Beginnen wir mit einer unbekannten Wahrscheinlichkeit. Da eine Zufallsvariable nur zwei Werte annehmen kann, beträgt die Summe der Wahrscheinlichkeiten der entsprechenden Ereignisse:
und seitdem .
Es bleibt nur noch zu finden..., das lässt sich leicht sagen :) Aber na ja, los geht's. Per Definition der mathematischen Erwartung: ![]() – Ersetzen Sie bekannte Mengen:
– Ersetzen Sie bekannte Mengen:
![]() – und aus dieser Gleichung lässt sich nichts mehr herausquetschen, außer dass man sie in die übliche Richtung umschreiben kann:
– und aus dieser Gleichung lässt sich nichts mehr herausquetschen, außer dass man sie in die übliche Richtung umschreiben kann: ![]()

oder: ![]()
Ich denke, Sie können die nächsten Schritte erraten. Lassen Sie uns das System zusammenstellen und lösen: 
Dezimalzahlen- Das ist natürlich eine völlige Schande; Multiplizieren Sie beide Gleichungen mit 10: 
und dividiere durch 2: 
Das ist besser. Aus der 1. Gleichung drücken wir aus: ![]() (das ist der einfachere Weg)– Setze in die 2. Gleichung ein:
(das ist der einfachere Weg)– Setze in die 2. Gleichung ein:
![]()
Wir bauen kariert und Vereinfachungen vornehmen: 
Mal: 
Das Ergebnis ist quadratische Gleichung, wir finden seine Diskriminante:
- Großartig!
und wir erhalten zwei Lösungen:
1) wenn ![]() , Das
, Das ![]() ;
;
2) wenn ![]() , Das .
, Das .
Die Bedingung wird durch das erste Wertepaar erfüllt. Mit hoher Wahrscheinlichkeit ist alles richtig, aber schreiben wir trotzdem das Verteilungsgesetz auf: 
und führen Sie eine Überprüfung durch, nämlich die Erwartung zu finden:



